GPT-Tico
Inferencia de ultra-velocidad con modelos LLM.
Soluciones de Inteligencia Artificial personalizadas que utilizan RAG (Generación Aumentada por Recuperación) para que la IA responda basándose en tus propios documentos o bases de datos con precisión militar.
Inferencia Groq
500 T/s
Arquitectura
Llama 3
Precisión RAG
96%
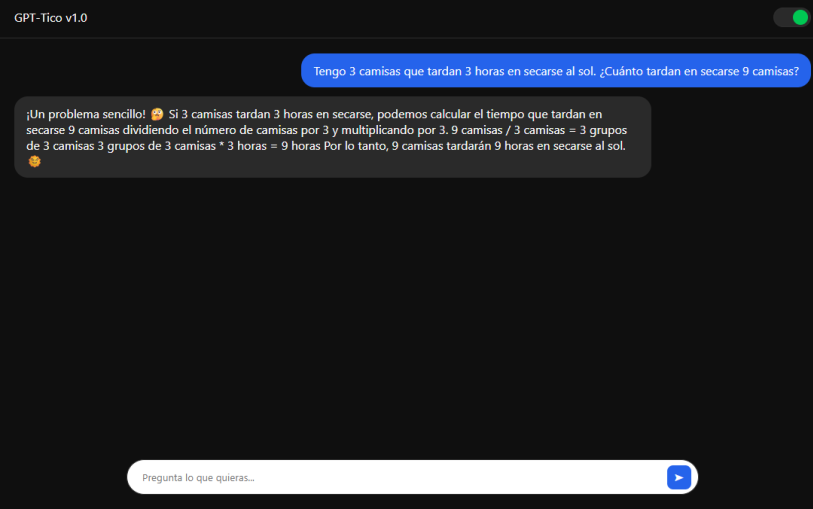
Búsqueda Semántica
No es un bot que solo adivina. Implemento bases de datos vectoriales que permiten a la IA buscar información real dentro de manuales, PDFs o bases de datos antes de generar una respuesta.
Inferencia Optimizada
Uso de hardware acelerado (LPUs) mediante Groq para lograr respuestas casi instantáneas, reduciendo la latencia de los LLM tradicionales en un 80%.
Inferencia de Modelo
const completion = await groq.chat.completions.create({
messages: [{
role: "system",
content: "Actúa como experto en..."
}],
model: "llama-3.1-70b-versatile",
temperature: 0.1,
stream: true
});
Groq Cloud
LangChain
Vectores